Criação de Gráficos Estatísticos
Existem diversos tipos de gráficos estatísticos, cada um adequado para representar diferentes tipos de dados e padrões
Dados utilizados
Vamos usar a fonte de dados Video Game Sales with Ratings com somente pontuações encontrada na área de Downloads
import pandas as pd
dados = pd.read_csv('video_games_scores.csv')
print(dados.columns)
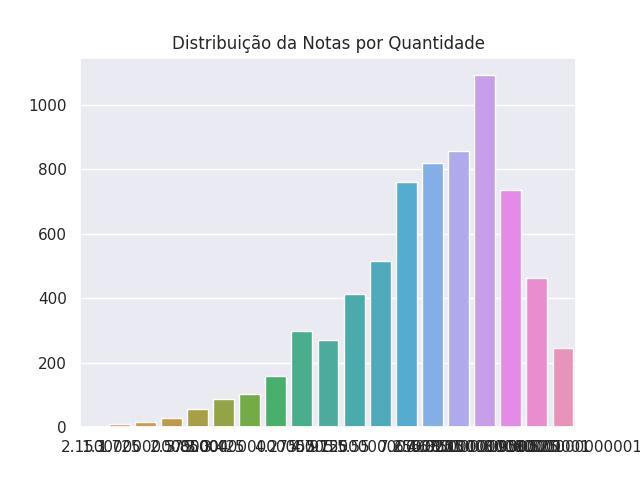
Histograma
Representa a distribuição de uma variável contínua. É uma forma de gráfico de barras em que as barras são usadas para mostrar a frequência ou a densidade dos valores em intervalos discretos (bins) ao longo de uma escala contínua
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dados = pd.read_csv('video_games_scores.csv')
score = dados['Critic_Score']
min = score.min()
max = score.max()
bins = 20
intervalos = np.arange(min, max, (max - min) / bins)
rotulos = []
distribuicao = []
for i in range(len(intervalos) - 1):
qtd = score[(score >= intervalos[i]) & (score < intervalos[i + 1])].count()
rotulos.append(intervalos[i])
distribuicao.append(qtd)
sns.set()
plt.title('Distribuição da Notas por Quantidade')
sns.barplot(x=rotulos, y=distribuicao)
plt.savefig('./video_game_distribuicao.jpg')
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dados = pd.read_csv('video_games_scores.csv')
sns.set()
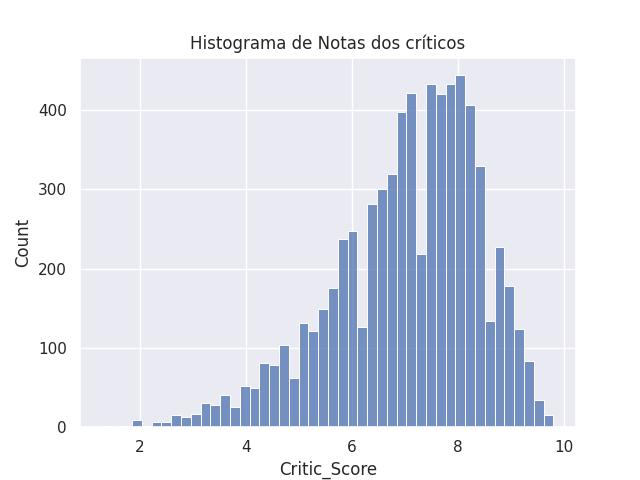
plt.title('Histograma de Notas dos críticos')
sns.histplot(x='Critic_Score', data=dados)
plt.savefig('./video_game_histogram.jpg')
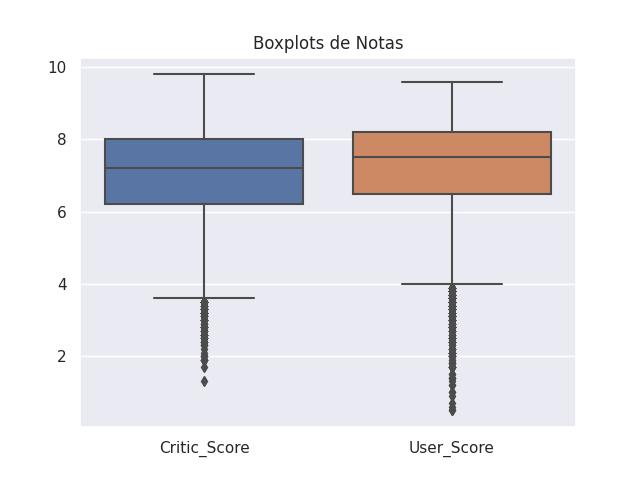
Boxplot
Representar a distribuição, a dispersão e a presença de outliers em um conjunto de dados
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dados = pd.read_csv('video_games_scores.csv')
sns.set()
plt.title('Boxplots de Notas')
sns.boxplot(data=dados[['Critic_Score', 'User_Score']])
plt.savefig('./video_game_boxplot.jpg')
Outliers
Valores que se afastam significativamente da maioria dos outros valores em um conjunto de dados. Esses valores são atípicos e geralmente são muito maiores ou menores do que a maioria dos outros dados
import numpy as np
import pandas as pd
dados = pd.read_csv('video_games_scores.csv')
quartiles = np.percentile(dados['Critic_Score'], [0, 25, 50, 75, 100])
print("Min", quartiles[0])
print("Q1", quartiles[1])
print("Mediana", quartiles[2])
print("Q3", quartiles[3])
print("Max", quartiles[4])
Existem várias maneiras para considerar os outliers a mais comum o Coeficiente Interquartil (IQR), uma vez e meia a distância entre o terceiro e primeiro quartil
IQR = 1.5 * (Q3 - Q1)
Podemos calcular os limites para identificar os outliers
import pandas as pd
dados = pd.read_csv('video_games_scores.csv')
q1 = dados['Critic_Score'].quantile(0.25)
q3 = dados['Critic_Score'].quantile(0.75)
iqr = q3 - q1
limit_bottom = q1 - 1.5 * iqr
limit_top = q3 + 1.5 * iqr
print("IQR", iqr)
print("Limit Bottom", limit_bottom)
print("Limit Top", limit_top)
Depende do conjunto de dados podemos remover os elementos de outliers
Correlação
O coeficiente varia de -1 a +1, quanto mais próximo do extremo demonstra a relação de significância, mas sempre se deve estar atento para não confundir correlação com causalidade
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dados = pd.read_csv('video_games_sales.zip', compression = 'zip')
corr = dados.corr(method='pearson', numeric_only=True)
sns.set()
sns.heatmap(corr, annot=True)
plt.savefig('./video_game_heatmap.jpg')
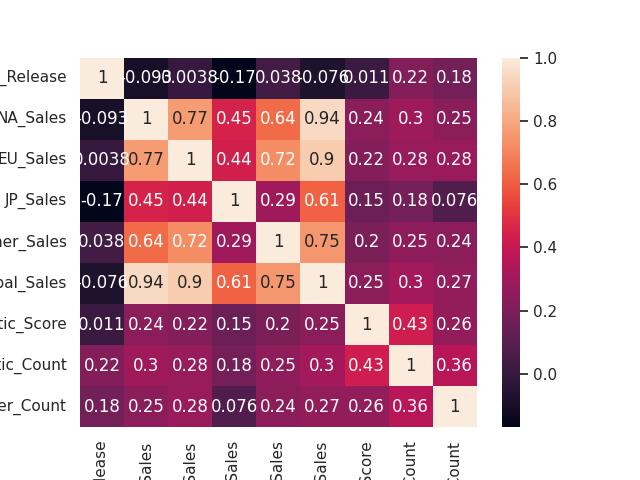
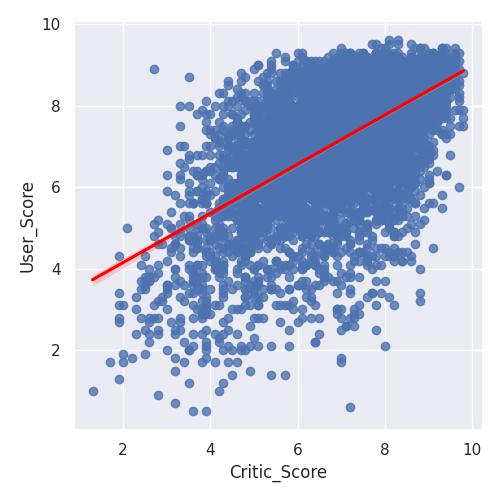
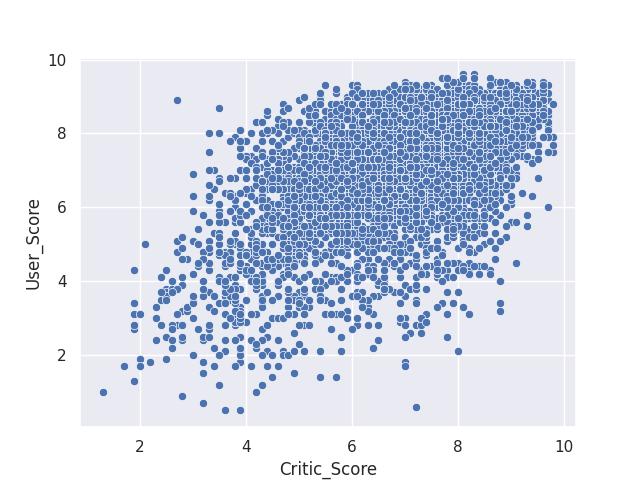
Gráfico de dispersão
Gráfico de dispersão por relação entre duas variáveis
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dados = pd.read_csv('video_games_scores.csv')
sns.set()
sns.scatterplot(x='Critic_Score', y='User_Score', data=dados)
plt.savefig('./video_game_scatter.jpg')
Regressão linear simples
Regressão linear é uam técnica de análise de dados que prevê o valor de dados desconhecidos usando outro valor de dados relacionado e conhecido
Y = β0 * X + β1 + ε
β0 e β1 são duas constantes desconhecidas que representam a inclinação da regressão, enquanto ε (épsilon) é o termo de erro
Representando com uma linha vermelha a regressão linear
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dados = pd.read_csv('video_games_scores.csv')
sns.set()
plt.title('Relação entre Notas Crítico x Usuários')
sns.lmplot(data=dados, x='Critic_Score', y='User_Score', line_kws={'color': 'red'})
plt.savefig('./video_game_lm.jpg')